本文共 5049 字,大约阅读时间需要 16 分钟。
素数也叫质数,凡是只能被1和自身整除的整数都叫做素数(数学概念),光是知道这个定义我们就可以写出列举某个范围内的素数的算法了。
//算法1func main() { t1 := time.Now().UnixNano() //计数器,每10个数换行 count := 0 //列举10000以内的素数 for i := 2; i <= 10000; i++ { isPrime := true for j := 2; j < i; j++ { if i%j == 0 { isPrime = false break } } if isPrime { count++ if count%10 != 0 { fmt.Printf("%d,", i) } else { fmt.Printf("%d\n", i) } } } t2 := time.Now().UnixNano() fmt.Printf("\n消耗时间:%d ms", (t2-t1)/1000000)}//---------------------------------------------------------算法平均用时(取10次测试结果平均值):95.8ms 可能大多数人会直接想到 “算法1”,这种写法直接就根据素数的定义来了(只能被1和自身【假设为n(下同)】整除,换言之就是[2,n-1]区间的数都不能整除)。
上述“算法1”只是我们初步的构思,运行结果肯定是没有问题,但是考虑到性能问题我们还可以进行优化: ①素数中除了2之外都是奇数,即都不能被2整除,因此循环测试数字的时候只需要测试奇数,这样可以省掉一半的数字测试; ②数字整除除数只能在被除数一半之内(这里依旧考虑[2,n-1]区间),比如:100的除数区间是[2,99],但实际上最大除数是50,超过一半的数字全都不能整除,因此50之后的数字全都没有测试的必要,这样一来又可以省掉一半的除法运算;//算法1【改进】func main() { t1 := time.Now().UnixNano() //计数器,每10个数换行 count := 1 fmt.Printf("%d,", 2) for i := 3; i <= 10000; i += 2 { isPrime := true for j := 2; j < i/2; j++ { if i%j == 0 { isPrime = false break } } if isPrime { count++ if count%10 != 0 { fmt.Printf("%d,", i) } else { fmt.Printf("%d\n", i) } } } t2 := time.Now().UnixNano() fmt.Printf("\n消耗时间:%d ms\n", (t2-t1)/1000000)}//---------------------------------------------------------算法平均用时(取10次测试结果平均值):75.3ms 从测试结果上看,平均时间提升了20ms左右。测试次数肯定是不够的,但是速度得到明显提升却是一个可想而知的结果。如果测试范围扩大到10w、100w、1000w,那么整个程序执行时间所体现出来的性能差距将会越来越大。(代码中为了统一,直接理所当然地将2作为素数输出,让循环从3开始,保证每次外层循环测试的都是奇数)
上述算法是以一种最简单,最直观的方式列举测试范围内的素数列(相信突然被要求“列出某范围内的素数列”,大多数人都会想到上面的算法)。但近日来我接触到了一种新的思路——“素数筛”。“素数筛”讲的是给定一个从1开始的、连续的数列,每次都从中筛选掉非素数,从而得到新数列,而新数列中的最小的数字即为本轮筛选的素数。 举个例子:给定一个数字区间[1,30]。 1 , 2,3 , 4,5 , 6,7 , 8,9 , 10 11 , 12 , 13,14 , 15 , 16 , 17 , 18 , 19 , 20 21 , 22 , 23 , 24 , 25 , 26 , 27 , 28 , 29 , 30 判断1不是素数,筛掉,得到新数列: 2,3 , 4,5 , 6,7 , 8,9 , 10 11 , 12 , 13,14 , 15 , 16 , 17 , 18 , 19 , 20 21 , 22 , 23 , 24 , 25 , 26 , 27 , 28 , 29 , 30 此时新数列最小数是2,为本轮筛选出来的素数。筛掉2的倍数,得到新数列:
3 , 5 ,7 , 9 11 , 13 , 15 , 17 , 19 21 , 23 , 25 , 27 , 29 此时新数列最小数是3,为本轮筛选出来的素数。筛掉3的倍数,得到新数列:
5 ,7 11 , 13 , 17 , 19 23 , 25 , 29 重复以上操作,最终就可以得到一个素数列,这就是“素数筛”的思想,通过每轮的筛选,得到新数列的首个元素(即最小元素)为本轮筛选出来的素数。 代码中体现为“将当前的数字去除以已知的素数列,如果均不能整除,则说明该数字的素数,并加入素数列中”。//算法2type primeNode struct { data int next *primeNode}func filterPrime(current int, prime *primeNode) bool { if prime == nil { return true } else { if prime.data != 0 && current%prime.data != 0 { return filterPrime(current, prime.next) } else { return false } }}func main() { t1 := time.Now().UnixNano() //计数器,每10个元素换行 count := 1 fmt.Printf("%v,", 2) //初始化一个节点,即首元结点,这里默认2为素数 pLink := &primeNode{ data: 2, } currentNode := pLink for i := 3; i <= 10000; i++ { if filterPrime(i, pLink) { currentNode.next = &primeNode{ data: i, } currentNode = currentNode.next count++ if count%10 == 0 { fmt.Printf("%v\n", i) } else { fmt.Printf("%v,", i) } } } t2 := time.Now().UnixNano() fmt.Printf("\n消耗时间:%d ms\n", (t2-t1)/1000000) fmt.Printf("素数数量:%d", count)}//---------------------------------------------------------算法平均用时(取10次测试结果平均值):55.2ms 代码中使用了链表结构,链表存的是整个素数列,链表中由若干个素数结点组成。data是数据域(即存数字的),next是指针域(用来指向下一个素数结点)。【tip:因为go语言中有指针的概念,所以这里使用了指针,像C、C++等有指针概念的通用。如果是Java语言的话这里可以考虑用ArrayList等长度可变的动态数组来添加素数构成素数列】
//算法3【并发版素数筛算法】//给出一个数字用来判断func numGiven(ch chan int) { for i := 2; i <= 10000; i++ { ch <- i }}func getPrime(chOld, chNew chan int, prime int) { go func() { for { if n := <-chOld; n%prime != 0 || n == 10000 { chNew <- n } } }()}func main() { t1 := time.Now().UnixNano() //计数器,每10个数字换行 count := 0 ch := make(chan int) go numGiven(ch) for { prime := <-ch if prime == 10000 { break } count++ if count%10 != 0 { fmt.Printf("%d,", prime) } else { fmt.Printf("%d\n", prime) } cho := make(chan int) getPrime(ch, cho, prime) ch = cho } t2 := time.Now().UnixNano() fmt.Printf("\n消耗时间:%d ms\n", (t2-t1)/1000000) fmt.Printf("素数个数:%d", count)}//---------------------------------------------------------算法平均用时(取10次测试结果平均值):77.4ms 上面算法4就是网上比较有代表性的go并发版素数筛,说是并发实际上还是串行执行的方式。getPrime函数里利用goroutine和channel的特性依次向上取值直到numGiven往通道中写入一个当前值n(n是当前值,下同),然后从第二个启动的goroutine中的channel读取到值并模2,即第二个goroutine此时是n%2,如果不能整除则将值写入另一个channel,这个channel被写入值后第三个goroutine解除阻塞并读取该channel中存的当前值n,并去模3,后面以此类推直到写入当前已开启的最后一个goroutine,在模prime不为0之后将当前值n写入通道,并由main函数中的通道ch读取输出。
这个算法比较容易混乱的地方在于多个goroutine并发导致读者可能会一时间不知道某个通道阻塞了该由哪个goroutine去执行,还有goroutine中的channel读取的值来自于哪里,写进去的值该由哪里读取? 图解值的流转顺序: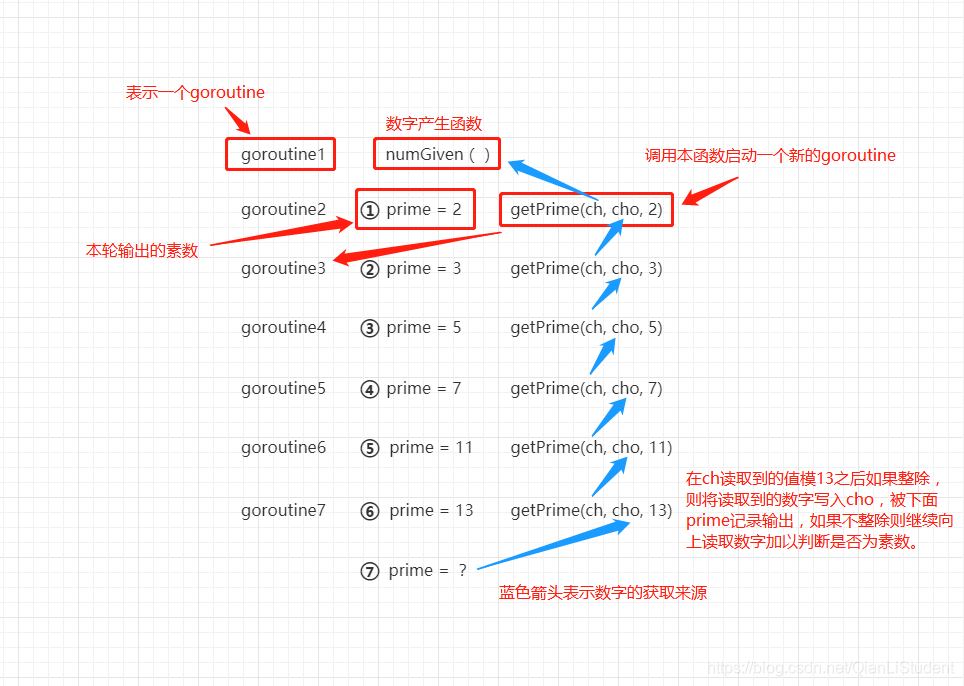 从图中可以看出,数字获取是依次向上直到来到数字产生函数numGiven()处读取到数字,然后依次向下做除以已知素数的判断。举例(结合上图):cho想要得到数字首先ch读取到一个数字,而ch的数字又来源于上一个goroutine中cho的数字,依次类推知道从numGiven()拿到一个数字写入第二个goroutine中的ch,这时候需要判断当前读取到的数字是否能整除本轮素数2,如果可以则重新获取ch中的数字,即重新从numGiven()拿一个新数字。如果不能整除本轮素数2,则将值写入cho,并由goroutine3中的ch读取。只要中间有一个素数被整除,则需要重新往上面拿到一个新值并重新做判断,直到已知的所有素数均不能被整除则认为该新数字为素数并输出。 虽然代码中用了大量的goroutine和channel实现goroutine之间的通信,看起来是一个并发的逻辑。但实际上goroutine之间的执行顺序是确定的,因此实质上还是一个串行逻辑。从程序的平均耗时来看确实也体现不出哪里的性能优势。
从图中可以看出,数字获取是依次向上直到来到数字产生函数numGiven()处读取到数字,然后依次向下做除以已知素数的判断。举例(结合上图):cho想要得到数字首先ch读取到一个数字,而ch的数字又来源于上一个goroutine中cho的数字,依次类推知道从numGiven()拿到一个数字写入第二个goroutine中的ch,这时候需要判断当前读取到的数字是否能整除本轮素数2,如果可以则重新获取ch中的数字,即重新从numGiven()拿一个新数字。如果不能整除本轮素数2,则将值写入cho,并由goroutine3中的ch读取。只要中间有一个素数被整除,则需要重新往上面拿到一个新值并重新做判断,直到已知的所有素数均不能被整除则认为该新数字为素数并输出。 虽然代码中用了大量的goroutine和channel实现goroutine之间的通信,看起来是一个并发的逻辑。但实际上goroutine之间的执行顺序是确定的,因此实质上还是一个串行逻辑。从程序的平均耗时来看确实也体现不出哪里的性能优势。 转载地址:http://qucb.baihongyu.com/